Working with Spark – Spark RDD

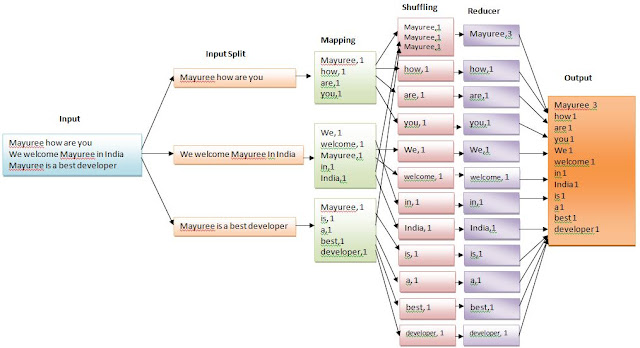
Introduction In my previous blog post, we are discussing about Hadoop Map Reduce. Now in this blog post we are going to discuss about Spark Fundamentals concept like RDD. RDD stands for Resilient Distributed Dateset , these are the elements that run and operate on multiple nodes to do parallel processing on a cluster. Hope it will be interesting. What is RDD According to Apache Spark documentation - " Spark revolves around the concept of a resilient distributed dataset (RDD), which is a fault-tolerant collection of elements that can be operated on in parallel. There are two ways to create RDDs: parallelizing an existing collection in your driver program, or referencing a dataset in an external storage system, such as a shared filesystem, HDFS, HBase, or any data source offering a Hadoop InputFormat ". RDDs are immutable elements, which means once we create an RDD we cannot change it. RDDs are fault tolerant as well, hence in case of any failure, they ...